Bounded flows
Constraining the support of a distribution explicitly can improve the accuracy of models. By doing so, we 1) prevent “leakage”, where the model assigns mass to regions outside the support, 2) guarantee valid samples for downstream applications, and 3) add inductive bias that often makes the target easier to learn.
The process used here to explicitly constrain the distribution involves three steps:
Preprocessing the data to map it to an unbounded domain using a bijection.
Learning the flow on the unbounded domain.
Transforming the flow back to the original domain using the inverse of the preprocessing bijection.
As an example, we’ll learn a two-dimensional beta distribution with parameters \(\alpha=0.4\) and \(\beta=0.4\), using samples from the distribution, such that the ground truth model is
Importing the required libraries.
[1]:
import jax
import jax.numpy as jnp
import jax.random as jr
import matplotlib.pyplot as plt
from flowjax.bijections import Affine, Chain, Invert, Tanh
from flowjax.distributions import Normal, Transformed
from flowjax.flows import masked_autoregressive_flow
from flowjax.train import fit_to_data
Generating the toy data.
[2]:
key, x_key = jr.split(jr.PRNGKey(0))
x = jr.beta(x_key, a=0.4, b=0.4, shape=(5000, 2)) # Supported on the interval [0, 1]^2
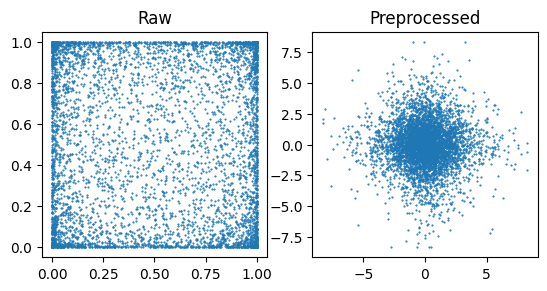
As \(x\) has bounded support and much of its mass near the boundaries, we choose a bijection to try and preprocess it to a more suitable form.
[3]:
eps = 1e-7 # Avoid potential numerical issues
preprocess = Chain(
[
Affine(
loc=-jnp.ones(2) + eps, scale=(1 - eps) * jnp.array([2, 2]),
), # [-1+eps, 1-eps]
Invert(Tanh(shape=(2,))), # arctanh (to unbounded)
],
)
x_preprocessed = jax.vmap(preprocess.transform)(x)
# Plot the data
fig, axes = plt.subplots(ncols=2)
plot_data = {"Raw": x, "Preprocessed": x_preprocessed}
for (k, v), ax in zip(plot_data.items(), axes, strict=True):
ax.scatter(v[:, 0], v[:, 1], s=0.3)
ax.set_title(k)
ax.set_aspect("equal")
We can now create and train the flow, fitting it to the preprocessed data, and transforming it back to the original bounded space
[4]:
key, subkey = jr.split(jr.PRNGKey(0))
# Create the flow
untrained_flow = masked_autoregressive_flow(
key=subkey,
base_dist=Normal(jnp.zeros(x.shape[1])),
transformer=Affine(),
)
key, subkey = jr.split(key)
# Train on the unbounded space
flow, losses = fit_to_data(
key=subkey,
dist=untrained_flow,
x=x_preprocessed,
learning_rate=5e-3,
max_patience=10,
max_epochs=70,
)
# Transform flow back to bounded space
flow = Transformed(flow, Invert(preprocess))
40%|████ | 28/70 [00:05<00:08, 5.23it/s, train=4.070985, val=4.0814867 (Max patience reached)]
For comparison, we can also train a flow directly on the raw data
[5]:
naive_flow, losses = fit_to_data(
subkey, untrained_flow, x, learning_rate=5e-3, max_patience=10, max_epochs=70,
)
66%|██████▌ | 46/70 [00:06<00:03, 7.03it/s, train=0.0039203074, val=-0.057805218 (Max patience reached)]
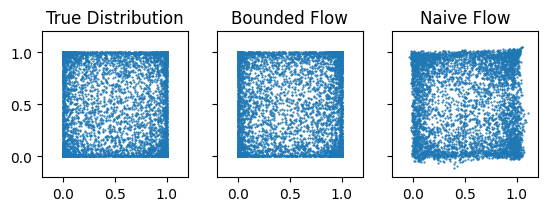
We can visualise the learned densities
[6]:
key, *subkeys = jr.split(key, 3)
samples = {
"True Distribution": x,
"Bounded Flow": flow.sample(subkeys[0], (x.shape[0],)),
"Naive Flow": naive_flow.sample(subkeys[1], (x.shape[0],)),
}
fig, axes = plt.subplots(ncols=3, sharex=True, sharey=True)
for (k, v), ax in zip(samples.items(), axes, strict=True):
ax.scatter(v[:, 0], v[:, 1], s=0.3)
ax.set_title(k)
ax.set_aspect("equal")
ax.set_xlim((-0.2, 1.2))
ax.set_ylim((-0.2, 1.2))
plt.show()
[ ]: